
Indice dei Contenuti
- Cause comuni di contenuti duplicati
- Contenuti duplicati per motivi tecnici
- Parametri per il filtraggio
- Tassonomie
- Pagine dedicate alle immagini
- Pagine dei commenti
- Localizzazione e hreflang
- Pagine dei risultati di ricerca indicizzabili
- Ambiente di staging/test indicizzabile
- Evitare di pubblicare contenuti in corso d’opera
- Parametri utilizzati per il tracciamento
- ID di sessione
- Versione stampabile
Cosa sono i contenuti duplicati?
In senso stretto, i contenuti duplicati si riferiscono a contenuti molto simili o uguali fra di loro, che sono presenti su più pagine del vostro sito web o di altri siti.
In generale, i contenuti duplicati sono contenuti che non aggiungono alcun valore agli utenti.
Pertanto, anche le pagine con un contenuto poco o per nulla corposo possono essere considerate contenuti duplicati.

Contenuti duplicati: cos'è la soglia di duplicazione
Nell’ambito di una strategia di contenuti SEO, la definizione di contenuto duplicato può essere sfuggente poiché non esiste una soglia fissa stabilita da Google e dagli altri motori di ricerca, anche se molti esperti SEO ritengono il contenuto passa da simile a duplicato se le parti in comune superano il 30% del totale del testo.
Infatti, Google e altri motori non forniscono un valore specifico, ma è cruciale creare contenuti originali che offrano valore unico ai lettori, e quindi evitare la copia diretta da altre fonti e lavorare per rendere il testo unico è la migliore pratica.
La duplicazione può verificarsi involontariamente, quindi è importante fare attenzione e andare nella direzione suggerita da Google con il sistema algoritmico Helpful Content.
Cause comuni di contenuti duplicati
I contenuti duplicati sono spesso dovuti a un server web o a un sito web non correttamente configurato.
Questi casi sono di natura tecnica e probabilmente non comporteranno mai una penalizzazione da parte di Google.
Tuttavia, possono danneggiare seriamente la visibilità del vostro sito, quindi è importante che la loro correzione diventi una priorità per chi si occupa di SEO.
Ma oltre alle cause tecniche, ci sono anche quelle umane: contenuti che vengono copiati di proposito e pubblicati altrove: questi casi possono comportare sanzioni se hanno un intento malevolo.
Vediamo ora più nel dettaglio le cause più comuni di contenuti duplicati.
Contenuti duplicati per motivi tecnici
Non-www vs www e HTTP vs https
Supponiamo di utilizzare il sottodominio www e HTTP.
La modalità preferita di servire i contenuti sarà quindi https://www.esempio.com.
Questo sarà il vostro dominio canonical (primario).
Tuttavia, se il vostro server web è configurato male, i vostri contenuti potrebbero essere accessibili anche attraverso:

Scegliete la vostra modalità di servire i vostri contenuti e implementate i reindirizzamenti 301 per le altre casistiche, in modo tale che portino alla versione preferita:
https://www.esempio.com.
Struttura dell'URL: minuscole/maiuscole e slash finali
Per Google, le URL sono sensibili alle maiuscole.
Ciò significa che https://esempio.com/url-a/ e https://esempio.com/url-A/ sono viste da Google come URL diverse.
Quando si creano i link, è facile commettere un errore di battitura, causando l’indicizzazione di entrambe le versioni dell’URL.
Si noti che per Bing gli URL non sono sensibili alle maiuscole e alle minuscole.
Una barra in avanti (/) alla fine di un URL è chiamata trailing slash.
Spesso le URL sono accessibili attraverso entrambe le varianti:
https://esempio.com/url-a e
https://esempio.com/url-a/

Scegliete una struttura preferita per le vostre URL e, per le versioni URL non canonical, implementate un reindirizzamento 301 alla versione URL canonical.
Pagine di tipo “index” (index.html, index.php)
A vostra insaputa, la vostra homepage potrebbe essere accessibile attraverso più URL perché il vostro server web è mal configurato.
Oltre a https://www.esempio.com, la vostra homepage potrebbe essere accessibile anche attraverso:
- https://www.esempio.com/index.html
- https://www.esempio.com/index.asp
- https://www.esempio.com/index.aspx
- https://www.esempio.com/index.php
Scegliete una URL primaria per la vostra homepage e implementate i reindirizzamenti 301 dalle versioni non canonical a quella canonical.
Nel caso in cui il vostro sito web utilizzi uno di questi URL per servire i contenuti, assicuratevi di rendere canonical queste pagine, in quando il reindirizzamento comporterebbe la rottura delle stesse.
Parametri per il filtraggio
I siti web spesso utilizzano parametri negli URL per offrire funzionalità di filtraggio.
Prendiamo ad esempio questo URL:
https://www.esempio.com/giochi/macchine?colour=nere
Questa pagina mostrerà tutte le macchinine nere.
Sebbene ciò vada bene per i visitatori, può causare gravi problemi ai motori di ricerca.
Le opzioni di filtro spesso generano una quantità virtualmente infinita di combinazioni quando è disponibile più di un’opzione di filtro.
Tanto più che anche i parametri possono essere riorganizzati.
Questi due URL mostrerebbero lo stesso identico contenuto:
- https://www.esempio.com/giochi/macchine?colour=nere&type=corsa
- https://www.esempio.com/giochi/macchine?type=corsa&colour=nere
Consiglio quindi di implementare URL canonical, una per ogni pagina principale non filtrata, per evitare contenuti duplicati e consolidare l’autorità della pagina filtrata.
Si noti che questo non previene i problemi di crawl budget.
In alternativa, è possibile utilizzare la funzionalità di gestione dei parametri in Google Search Console e Bing Webmaster Tools per indicare ai rispettivi crawler come gestire i parametri.
Tassonomie
Una tassonomia è un metodo per organizzare e/o classificare i contenuti.
Sono spesso utilizzate nei blog per supportare categorie e tag.
Supponiamo di avere un post sul blog che appartiene a tre categorie.
Il post può essere accessibile in tutte e tre:
- https://www.esempio.com/categoria-a/topic/
- https://www.esempio.com/categoria-b/topic/
- https://www.esempio.com/categoria-c/topic/

Assicuratevi di scegliere una di queste categorie come principale e fate in modo che le altre vengano canonicalizzate ad essa utilizzando l’URL canonico.
Pagine dedicate alle immagini
Alcuni sistemi di gestione dei contenuti creano una pagina separata per ogni immagine: la conseguenza è che tale pagina spesso si limita a mostrare l’immagine in una pagina altrimenti vuota.
Poiché questa pagina non ha altri contenuti, è molto simile a tutte le altre pagine di immagini e quindi equivale a un contenuto duplicato.
Se possibile, disabilitare la funzione per dare alle immagini pagine dedicate. Se non è possibile, la cosa migliore è aggiungere un attributo meta robots “noindex” alla pagina.
Pagine dei commenti
Se sul vostro sito web sono abilitati i commenti, è possibile che vengano impaginati automaticamente dopo un certo numero di commenti. Le pagine dei commenti impaginate mostreranno il contenuto originale; solo i commenti in fondo saranno diversi.
Ad esempio, l’URL dell’articolo che mostra i commenti 1-20 potrebbe essere https://www.esempio.com/categoria/topic/, e
- https://www.esempio.com/categoria/topic/commenti-2/ per i commenti 21-40
- https://www.esempio.com/categoria/topic/commenti-3/ per i commenti 41-60.
Utilizzate una paginazione che sia efficace a segnalare che si tratta di una serie di URL che seguono una logica di paginazione.
Localizzazione e hreflang
Quando si parla di localizzazione, i problemi di contenuto duplicato possono sorgere quando si utilizza lo stesso identico contenuto per rivolgersi a persone di regioni diverse che parlano la stessa lingua.
Ad esempio, se avete un sito web dedicato al mercato canadese e uno per il mercato statunitense, entrambi in inglese, è probabile che ci siano molte duplicazioni nei contenuti.
Google è bravo a rilevarlo e di solito accorpa questi risultati.
L’attributo hreflang aiuta a prevenire i contenuti duplicati.
Quindi, se utilizzate gli stessi contenuti per pubblici diversi, assicuratevi di implementare l‘hreflang come parte di una solida strategia SEO internazionale.
Pagine dei risultati di ricerca indicizzabili
Molti siti web offrono funzionalità di ricerca che consentono agli di cercare tra i contenuti del sito.
Le pagine su cui vengono visualizzati i risultati della ricerca sono tutte molto simili e nella maggior parte dei casi non forniscono alcun valore aggiunto ai motori di ricerca.
Per questo motivo non è opportuno che siano indicizzabili da essi.
Il mio consiglio, quindi, è di impedire ai motori di ricerca di indicizzare le pagine dei risultati di ricerca interna utilizzando l’attributo meta robots noindex.
Inoltre, in generale, è buona norma non inserire link interni alle pagine dei risultati della ricerca.
Nel caso in cui una grande quantità di pagine di risultati di ricerca interne siano oggetto di crawl da parte dei motori di ricerca, si consiglia di bloccare ad essi l’accesso utilizzando il file robots.txt.
Ambiente di staging/test indicizzabile
Anche l’utilizzo di ambienti di staging per l’implementazione e il test di nuove funzionalità sui siti web è una buona pratica.
Spesso, però, questi ambienti vengono lasciati erroneamente accessibili e indicizzabili ai motori di ricerca.
Consiglio quindi di utilizzare l’autenticazione HTTP per impedire l’accesso agli ambienti di staging/testing.
Un ulteriore vantaggio è che si impedisce anche alle persone sbagliate di accedervi.
Se il vostro ambiente di staging/testing dovesse essere indicizzato, vi consiglio di leggere questo thread sulla sezione Help di Google Console Console.
Anche questo articolo offre delle indicazioni precise su come risolvere il problema.
Evitare di pubblicare contenuti in corso d'opera
Quando si crea una nuova pagina che contiene pochi contenuti, salvarla senza pubblicarla ancora: spesso non fornirà alcun valore.
Salvate le pagine non finite come bozze.
Se dovete pubblicare pagine con contenuti limitati, impedite ai motori di ricerca di indicizzarle: utilizzate l’attributo meta robots noindex.
Parametri utilizzati per il tracciamento
I parametri sono comunemente utilizzati anche a scopo di tracciamento.
Ad esempio, quando si condividono gli URL su Twitter, viene aggiunta la fonte (source) all’URL.
Questa è un’altra causa di contenuti duplicati.
Prendiamo ad esempio questo URL che è stato twittato utilizzando Buffer:
Your SEO guide to finding and fixing broken internal links
È una buona pratica implementare URL canonici autoreferenziali sulle pagine.
Se l’avete già fatto, questo risolve il problema.
Tutte le URL con questi parametri di tracciamento devono essere canonicalizzati (tramite un‘impostazione predefinita) alla versione senza parametri.
ID di sessione
Le sessioni possono memorizzare le informazioni sui visitatori per l’analisi del web.
Se a ogni URL richiesto da un visitatore viene aggiunto un ID di sessione, si creano molti contenuti duplicati, perché il contenuto di questi URL è esattamente lo stesso.
Ad esempio, quando si fa clic su una versione localizzata del nostro sito web, aggiungiamo una variabile di sessione di Google Analytics, come https://www.searchengine.com/?_ga=2.41368868.703611965.1506241071-1067501800.1494424269 .
Questa mostra la homepage con gli stessi contenuti, ma con un URL diverso.
Ancora una volta, è una buona pratica implementare URL canonici autoreferenziali sulle pagine.
Se già lo fate, avete risolto il problema.
Tutte le URL con questi parametri di tracciamento vengono canonicalizzati per impostazione predefinita alla versione senza parametri
Versione stampabile
Quando le pagine hanno una versione adatta alla stampa in un URL separato, ci sono essenzialmente due versioni dello stesso contenuto.
Immaginate di trovare le seguenti URL:
- https://www.esempio.com/pagin-1/ e
- https://www.esempio.com/print/pagina-1/
Il mio consiglio è di implementare un URL canonico che porti dalla versione print friendly alla versione normale della pagina.
Contenuti duplicati causati da contenuti copiati
Pagine di atterraggio per la ricerca a pagamento
La ricerca a pagamento richiede pagine di destinazione dedicate che mirano a parole chiave specifiche.
Le landing page sono spesso copie di pagine originali, che vengono poi adattate per puntare a queste parole chiave specifiche.
Poiché queste pagine sono molto simili, producono contenuti duplicati se vengono indicizzate dai motori di ricerca.
Impedire ai motori di ricerca di indicizzare le pagine di destinazione implementando l’attributo meta robots noindex.
In generale, la prassi migliore è quella di non linkare le landing page delle vostre campagne a pagamento e di non includerle nella sitemap XML.
Altri soggetti che copiano i vostri contenuti
I contenuti duplicati possono anche derivare da altri siti che copiano i vostri contenuti e li pubblicano altrove.
Questo è un problema soprattutto se il vostro sito web ha una bassa autorità di dominio e quello che copia i vostri contenuti ha un’autorità di dominio superiore.
I siti web con un’autorità di dominio più elevata vengono spesso sottoposti a crawling più frequente, con il risultato che il contenuto copiato viene crawlato per primo sul sito web di colui che ha copiato il contenuto.
Questo potrebbe quindi essere percepito come l’autore originale e posizionarsi al di sopra di voi.
Assicuratevi che gli altri siti web vi riconoscano, sia implementando un URL canonico che porti alla vostra pagina, sia linkando la vostra pagina.
Se non sono disposti a farlo, potete inviare una richiesta DMCA a Google e/o intraprendere un’azione legale.
Copiare contenuti da altri siti web
Anche la copia di contenuti da altri siti web è una forma di contenuto duplicato.
Google ha documentato come gestire al meglio questo aspetto dal punto di vista SEO: collegamento alla fonte originale, combinato con un URL canonical o un tag meta robots noindex.
Tenete presente che non tutti i proprietari di siti web sono contenti che voi mettiate in rete i loro contenuti.
Quindi, il mio consiglio, è chiedere il permesso di utilizzare i contenuti di altri se non volete incorrere in spiacevoli sorprese.
Come trovare i contenuti duplicati
Ora che abbiamo esaminato le principali cause di contenuti duplicati per la SEO, vediamo quali sono i modi per trovarli all’interno del nostro sito.
Esistono diversi modi per farlo.
Di seguito, vi mostro tre modi gratuiti.
Google Search Console
Google Search Console è un potente strumento gratuito a vostra disposizione che può aiutarvi moltissimo a ottenere visibilità sulle prestazioni delle vostre pagine web nei risultati di ricerca.
Utilizzando la scheda Risultati di ricerca alla voce Prestazioni, potrete trovare le URL che potrebbero causare problemi di contenuto duplicato.
Fate attenzione a questi problemi comuni:
- Versioni HTTP e HTTPS della stessa URL
- Versioni www e non www della stessa URL
- Versioni mobile e desktop della stessa URL
- URL con e senza barra finale “/”.
- URL con e senza parametri di query
- URL con e senza maiuscole
- Query a coda lunga per le quali si posizionano più pagine diverse.
Di seguito, vi mostro un esempio di ciò che potreste trovare:
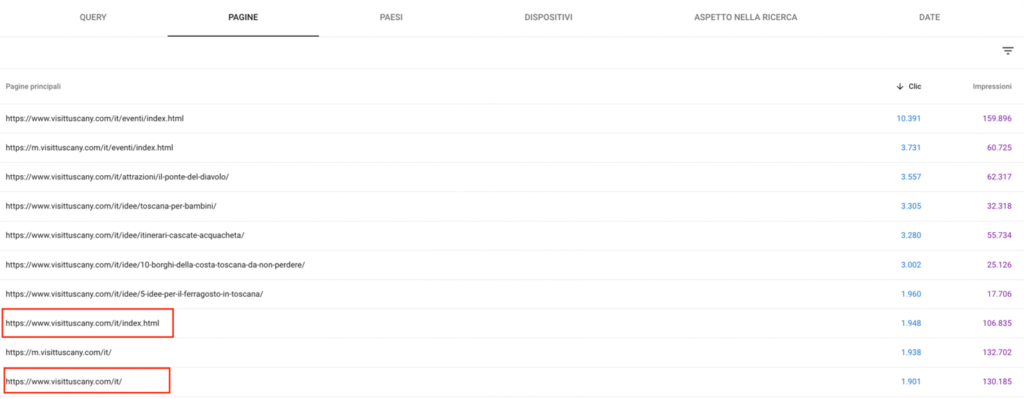
Dall’immagine qui sopra, si può notare che la versione /it/ e quella /it/index.html della homepage di VisitTuscany.com si posizionano entrambe nei risultati di ricerca e ricevono clic.
Tenete traccia degli URL che trovate con problemi di duplicazione.
In seguito, vedremo come risolverli!
"Ricerca "Sito:
Andando su Google Search e digitando “site:” seguito dall’URL del vostro sito web, potete vedere tutte le pagine che Google ha indicizzato e che hanno il potenziale per posizionarsi nei risultati di ricerca.
Ecco cosa appare digitando “site:visittuscany.com/en/ blog” nella barra di ricerca di Google:
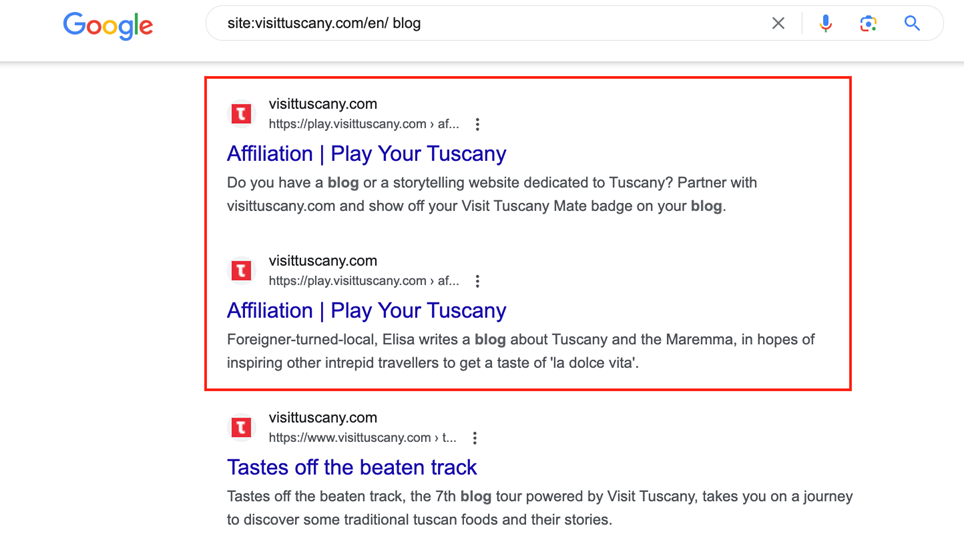
Come si può vedere, appaiono due pagine quasi identiche.
Si tratta di una cosa importante da notare: sebbene queste pagine non siano tecnicamente duplicate, contengono lo stesso title tag (“Affiliation | Play Your Tuscany”), il che può portare alla cannibalizzazione delle parole chiave e alla competizione per il posizionamento tra le due pagine. In questo caso, la duplicazione è causata da un filtro presente sulla pagina canonical: https://play.visittuscany.com/en/play/affiliation/ alla quale non viene applicato un “blocco” tramite robots.txt.
Duplicate Content Checker
SEO Review Tools ha creato uno strumento gratuito di controllo dei contenuti duplicati per aiutare i siti web a combattere lo scraping dei contenuti.
Inserendo la vostra URL nel loro strumento di controllo, potrete ottenere una panoramica degli URL esterni e interni che duplicano l’URL inserito.
Scoprire i contenuti duplicati esterni è molto importante.
Il contenuto duplicato esterno può verificarsi quando il dominio di un altro sito web “ruba” il contenuto del vostro sito, una tattica nota anche come content scraping.
Quando scoprite situazioni di questo tipo, consiglio di inviare una richiesta a Google e far rimuovere la pagina duplicata.
Perché i contenuti duplicati sono dannosi per la SEO?
I contenuti duplicati sono dannosi per due motivi:
- Quando sono disponibili diverse versioni di contenuti, è difficile per i motori di ricerca determinare quale indicizzare e quindi mostrare nei risultati di ricerca. Questo riduce le prestazioni di tutte le versioni del contenuto, poiché sono in competizione tra loro.
- I motori di ricerca avranno difficoltà a consolidare le metriche dei link (autorità, rilevanza e fiducia) per il contenuto, soprattutto quando altri siti web rimandano a più “versioni” di quel contenuto.
Google: I contenuti duplicati NON sono un fattore di ranking negativo
In base a recenti dichiarazioni da parte di John Mueller, fatte durante una registrazione dell’hangout Google SEO office-hours del 29 gennaio 2021 (link al video qui sotto), i contenuti duplicati non sono un fattore di ranking negativo.
È normale per i siti ospitare una certa quantità di contenuto duplicato e gli algoritmi di Google sono progettati per gestirlo.
Se intere parti del contenuto su un sito sono duplicate, Google opterà per una e non mostrerà l’altra.
Le copie multiple della stessa pagina non inviano segnali di ranking negativo.
Tuttavia, le pagine duplicate possono gonfiare un sito e consumare il crawl budget.
Sezioni di contenuto ripetute in tutto un sito, come il contenuto nell’intestazione o nel piè di pagina, non invieranno nemmeno segnali di ranking negativo.
In generale, se Google trova esattamente la stessa informazione su molte pagine web, cercherà di trovare la pagina corrispondente migliore quando qualcuno cerca quella specifica informazione.
Solo nei rari casi in cui Google percepisca che il contenuto duplicato potrebbe essere mostrato con l’intento di manipolare i ranking e ingannare gli utenti, verranno apportate le opportune modifiche nell’indicizzazione e nel ranking dei siti coinvolti.
Lo stesso contenuto in formati diversi non è duplicato
In un’altra occasione, John Mueller ha inoltre sottolineato come un contenuto identico pubblicato in formati diversi, come un video e un post di blog, non viene considerato contenuto duplicato.
I proprietari di siti web possono tranquillamente riproporre un video come articolo senza preoccuparsi che Google possa vedere i due contenuti come identici.
Il tema è stato sollevato durante uno streaming del 22 gennaio 2021 (ho messo il video sotto), quando un proprietario di un sito che gestisce un canale YouTube ha chiesto se ci fosse qualche problema nell’utilizzare lo stesso testo di un post del blog in un video.
John Mueller ha spiegato che Google non è in grado di effettuare un’analisi del testo dei video e di mappare il testo sulle pagine web.
Se un video ripete parola per parola ciò che è stato affermato in un post del blog, sono considerati contenuti differenti.
Contenuti simili presentati in formati diversi non saranno visti come contenuto duplicato, in quanto Google sa bene che gli utenti possono voler fruire della medesima informazione in formati diversi.
A volte le persone che cercano su Google vogliono leggere un articolo, altre volte vogliono guardare un video.
Mueller incoraggia la riproposizione del contenuto in questo modo e suggerisce ai proprietari di siti di continuare a farlo.
Posso ricevere una penalizzazione per contenuti duplicati?
La presenza di contenuti duplicati può danneggiare le prestazioni SEO, ma non comporta una penalizzazione da parte di Google, a patto che non venga copiato intenzionalmente il sito di qualcun altro.
Se siete un proprietario di un sito web con qualche problema tecnico e non state cercando di ingannare Google, non dovete preoccuparvi di incorrere in una penalizzazione da parte di Google.
Se avete copiato grandi quantità di contenuti altrui, invece, il discorso cambia.
Ecco cosa ha specificato Google al riguardo:
La presenza di contenuti duplicati su un sito non è motivo di intervento sul sito stesso, a meno che non risulti che l’intento del contenuto duplicato sia quello di ingannare e manipolare i risultati dei motori di ricerca.
Se il vostro sito soffre di problemi di contenuti duplicati e non seguite i consigli sopra elencati, facciamo un buon lavoro nello scegliere una versione del contenuto da mostrare nei risultati di ricerca.
Di seguito, condivido il pensiero di Patrick Stox, Technical SEO di Ahrefs:

“Il 25-30% del web è costituito da contenuti duplicati, e va bene così! Google non vi penalizzerà, ma credo fermamente che dovreste specificare come gestire i contenuti duplicati. Detto ciò, anche se non fate nulla, Google ha molti modi per risolvere i problemi di duplicazione. Non mi preoccuperei troppo di questo aspetto, a meno che non stiate facendo qualcosa che potrebbe causare gravi problemi, come lo scraping di contenuti da altri siti web.”
Qual è la soluzione più comune per gestire i contenuti duplicati?
In molti casi, il modo migliore per risolvere i contenuti duplicati è l’implementazione di reindirizzamenti 301 dalle versioni non preferite degli URL a quelle preferite.

Quando le URL devono rimanere accessibili ai visitatori, non si può usare il redirect, ma si può usare un URL canonical oppure la direttiva noindex.
L’URL canonical consente di consolidare alcuni segnali, mentre la direttiva robots noindex non lo fa.
Scegliete con cura l’arma con cui combattere i contenuti duplicati, perché tutte hanno pro e contro. Non esiste un approccio “unico”. 🙂
Strumenti per verificare la presenza di contenuti duplicati
Ricerca “spot” su Google
Un modo rapido per verificare se una pagina può essere considerata duplicata è copiare una decina di parole dall’inizio di una frase e incollarle con le virgolette su Google.
Se si esegue un test su una pagina del proprio sito web, ci si aspetta che venga visualizzata solo la propria pagina, possibilmente senza altri risultati.
Se invece vengono visualizzati altri siti web, Google indica che ritiene che la fonte originale sia il risultato che viene mostrato per primo.
Qualora non si trattasse del vostro sito web, potreste avere un problema di contenuti duplicati.
Ripetete questo processo testando altri frammenti di testo presi dal vostro sito su Google.
Strumenti gratuiti per verificare la presenza di contenuti duplicati
Quando scrivete i vostri contenuti, potreste involontariamente renderli troppo simili a quelli già pubblicati.
È sempre una buona idea ricontrollare tutto ciò che scrivete utilizzando uno strumento di controllo di plagio per assicurarvi che il vostro contenuto sia considerato unico.
Molti di questi strumenti sono disponibili gratuitamente.
Ecco alcuni esempi:
Copyscape – Questo strumento è in grado di verificare rapidamente e in pochi secondi i contenuti che avete scritto rispetto a quelli già pubblicati. Lo strumento di confronto evidenzierà i contenuti che risultano duplicati e vi farà sapere quale percentuale dei vostri contenuti corrisponde a quelli già pubblicati.
Plagspotter – Questo strumento è in grado di identificare le pagine di contenuto duplicate sul web. È un ottimo strumento per trovare i plagiatori che hanno rubato i vostri contenuti. Consente inoltre di monitorare automaticamente le URL su base settimanale per identificare i contenuti duplicati.
Duplichecker – Questo strumento verifica rapidamente l’originalità dei contenuti che intendete pubblicare sul vostro sito. Gli utenti registrati possono effettuare fino a 50 ricerche al giorno.
Siteliner – È un ottimo strumento in grado di controllare una volta al mese l’intero sito per verificare la presenza di contenuti duplicati. Può anche verificare la presenza di link rotti e identificare le pagine più importanti per i motori di ricerca.
Smallseotools – Sono disponibili diversi strumenti SEO, tra cui un controllore di plagio che identifica frammenti di contenuti identici.
Strumenti premium per il controllo del plagio
Gli strumenti di controllo da plagio premium sono in grado di verificare la presenza di contenuti duplicati utilizzando algoritmi avanzati.
Fanno in modo che il vostro lavoro non sia attribuito a qualcuno che non l’ha scritto.
Gli strumenti premium per il plagio offrono dei report che possono verificare la prova dell’originalità e che possono essere salvati in formato PDF.
Alcuni esempi di strumenti premium per verificare la presenza di contenuti duplicati sono:
I vostri contenuti sono stati oggetto di scraping?
I contenuti del vostro sito web devono essere completamente originali e gli strumenti di cui sopra possono aiutarvi a verificare che non abbiate inavvertitamente reso i vostri contenuti troppo simili a quelli presenti sul sito di qualcun altro.
L’altro motivo per controllare continuamente la presenza di contenuti duplicati è che ci sono siti web che rubano intenzionalmente contenuti dai siti web di qualcun altro per usarli sul proprio.
Questo avviene in genere utilizzando software automatizzati.
Come potete individuare gli scraper di contenuti?
Cosa dovete fare se scoprite che i vostri contenuti sono stati copiati e pubblicati sul sito di qualcun altro?
Modi per catturare gli scraper di contenuti
L’uso regolare di strumenti premium per il plagio può aiutarvi a individuare i contenuti che avete scritto sul sito di qualcun altro.
Esistono altre opzioni per individuare i contenuti che sono stati copiati.
I trackback in WordPress possono comparire nello spam se si utilizza Askimet.
Se i vostri contenuti includono sempre dei link ad altri vostri post, potreste essere in grado di trovare gli scraper di contenuti in questo modo.
Utilizzate gli strumenti per i Webmaster e controllate i link al vostro sito.
Quando avete un gran numero di link da un particolare sito, potreste scoprire che alcuni dei vostri contenuti sono stati copiati sul loro. L’unico modo per esserne certi è visitare il loro sito e controllare quali pagine rimandano al vostro sito.
Utilizzate Google Alerts per essere avvisati se uno dei titoli dei vostri post appare sul web dopo che il vostro contenuto è già stato pubblicato.
Più vi affermate come autorità nella vostra nicchia, più vi accorgerete che coloro che non hanno ancora stabilito la propria voce o autorità vogliono prendere in prestito la vostra.
Questa pratica, purtroppo, permette loro di fornire informazioni autorevoli sul proprio blog senza doversi impegnare a creare contenuti di qualità.
Cosa fare con gli scraper di contenuti
Lo scraping di contenuti non è etico.
Una scoperto che i vostri contenuti sono stati oggetto di scraping, avete un paio di opzioni.
- Contattate il proprietario del sito web che ha pubblicato il vostro contenuto e fategli sapere che avete trovato il vostro contenuto sul suo sito. Il proprietario del sito potrebbe non essere a conoscenza del fatto che un contenuto rubato è stato aggiunto al suo sito, quindi concedetegli il beneficio del dubbio. Potete contattarlo attraverso il suo modulo di contatto o attraverso una delle piattaforme di social media sulle quali è attivo.
Se si tratta di un sito di alta qualità, offrite loro la possibilità di mantenere il contenuto, dandovi il merito di essere l’autore e un link al vostro sito. Un’altra possibilità è quella di offrire una revisione dell’articolo in cambio di un link. Se si tratta di un sito di bassa qualità, comunicate che volete che il vostro contenuto venga rimosso immediatamente.
- Se non c’è un modo apparente per contattare il proprietario del sito web, fate una ricerca Whois. In questo modo si potrà sapere chi è il proprietario, a meno che non sia un sito registrato privatamente. Se non riuscite ancora a scoprire chi è il proprietario del sito, potrete scoprire chi lo ospita utilizzando lo strumento gratuito https://digital.com/who-is-hosting-this/ . Contattate la società di hosting e informatela che il proprietario del sito sta pubblicando contenuti protetti da copyright. Le società di web hosting prendono sul serio questo tipo di reclami e offriranno assistenza in modo tempestivo.
Protezione dei contenuti con il DMCA
Avete il diritto di copyright su tutti i contenuti originali che pubblicate sul vostro sito.
Un modo per proteggervi è quello di inserire un badge DMCA sul proprio sito.
Il DMCA dichiara che effettuerà un takedown gratuito se il vostro contenuto viene rubato mentre è protetto da uno dei suoi badge.
Il DMCA aiuta a scoraggiare i ladri e offre strumenti per aiutarvi a individuare le copie non autorizzate dei vostri contenuti sul sito di qualcun altro.
Il DMCA elimina rapidamente i contenuti plagiati, comprese le immagini e i video.
Suggerimenti per prevenire i contenuti duplicati
Per evitare la creazione di contenuti duplicati, assicuratevi di essere proattivi nell’impostare le vostre pagine. Ecco due cose che potete fare per combattere la creazione di contenuti duplicati:
Coerenza dei collegamenti interni
Una buona strategia di internal linking è fondamentale per valorizzare le pagine più importanti e strategiche del vostro sito.
Tuttavia, è importante assicurarsi di essere coerenti con la struttura degli URL nella propria strategia di linking.
Ad esempio, se si decide che la versione canonica della propria homepage è www.esempio.com/, tutti i link interni alla homepage dovranno essere https://www.esempio.com/ anziché https://esempio.com/ (la differenza è data dall’assenza del dominio di primo livello www).
Mantenete la coerenza con le seguenti variazioni comuni degli URL:
- HTTP vs HTTPS
- www vs non www
- Barra finale: esempio.com vs esempio.com/
Se un link interno utilizza uno slash finale, ma un altro link alla stessa pagina non lo fa, si crea un contenuto duplicato della pagina.
Utilizzare un tag canonical autoreferenziale
Per evitare lo scraping dei contenuti, è possibile aggiungere il meta tag rel=canonical autorefenziale; in questo modo si crea una pagina auto-canonica.
L’aggiunta del tag rel=canonical indicherà ai motori di ricerca che la pagina corrente è il contenuto originale.
Quando un sito viene copiato, il codice HTML viene preso dal contenuto originale e aggiunto a un URL diverso.
Se nel codice HTML è incluso un tag rel=canonical, è probabile che venga copiato anche nel sito duplicato, conservando così la pagina originale come versione canonica.
È importante notare che si tratta di una salvaguardia aggiuntiva che funziona solo se gli scraper di contenuti copiano quella parte del codice HTML.

FAQ
Plagio vs. content curation: che differenza c’è?
La content curation consiste nel riproporre parti di testi altrui offrendo del valore aggiuntivo e citando l’autore in qualità di fonte.
Il plagio si verifica quando si presentano i contenuti di un’altra persona come propri, costituendo un atto di contraffazione e violazione dei diritti d’autore. L’omissione della citazione delle fonti è considerata un atto di plagio.
Condividere un articolo sui social media genera contenuti duplicati?
Dal punto di vista tecnico, si tratta di un esempio di contenuto duplicato. Tuttavia, è importante notare che Google ha una vasta esperienza nel gestire simili scenari, dato che numerosi siti condividono regolarmente informazioni su piattaforme come Facebook e Twitter. Per affrontare questa situazione, è possibile adottare alcune precauzioni, come inserire un link di riferimento alla fonte originale e implementare il link canonical.
Il Panda Update di Google ha colpito i siti con contenuti duplicati?
A partire dal Panda update (febbraio 2011), l’impatto dei contenuti duplicati è diventato molto più serio.
In passato, i contenuti duplicati potevano danneggiare soltanto i contenuti stessi. Se si aveva un contenuto duplicato, poteva essere integrato o filtrato. In casi estremi, un gran numero di contenuti duplicati poteva gonfiare l’indice o causare problemi di crawling.
Successivamente però, Panda ha reso la valutazione dei contenuti duplicati parte di una più ampia equazione di qualità dei siti: ora un problema di contenuti duplicati può avere un impatto sull’intero sito web.
Se venite colpiti da Panda, le pagine non duplicate possono perdere potere di ranking, smettere di posizionarsi del tutto o addirittura essere eliminate dall’indice.
Pertanto, i contenuti duplicati non sono più un problema isolato!
Quanto contenuto duplicato è accettabile su un sito?
La risposta a questa domanda dipende dal caso specifico.
Tuttavia, se vuoi che il tuo sito si posizioni bene, devi ridurre al minimo i contenuti simili o identici pubblicati su più pagine.
Devi assicurarti che il contenuto di ogni pagina sia utile per i visitatori e non sia copiato da altre risorse online.
Inoltre, secondo Matt Cutts (ex Head of the web spam team presso Google), il 25%-30% del web è costituito da contenuti duplicati. Google non considera i contenuti duplicati come spam e non penalizzerà il vostro sito, a meno che non siano finalizzato a manipolare i risultati di ricerca.
Risolvendo i problemi relativi ai contenuti duplicati SEO la visibilità su Google ne trarrà beneficio?
Sì, perché correggendo i problemi di contenuto duplicato direte a Google (e agli altri motori di ricerca) quali sono le pagine che dovrebbero realmente scansionare, indicizzare e posizionare. Inoltre, eviterete che i motori di ricerca spendano il crawl budget per pagine non rilevanti a fini SEO e di business.
Conclusioni
Navigando attraverso le sfide e le implicazioni dei contenuti duplicati SEO, questa guida ha esplorato la complessità e la rilevanza di questa problematica, dalla sua definizione alla soluzione di problemi tecnici specifici, come configurazioni di URL e gestione delle tassonomie.
Con un occhio di riguardo al Panda Update di Google, che ha elevato l’importanza di gestire efficacemente i contenuti duplicati, e all’importanza di minimizzare i contenuti identici o simili, ho voluto sottolineare l’essenzialità di strategie SEO attente e misurate per assicurare visibilità e valore unico in ogni pagina web.
Risolvere i problemi di contenuti duplicati non solo ottimizza l’utilizzo del crawl budget dei motori di ricerca ma migliora anche la percezione di unicità e autorevolezza del vostro sito web, fondamentale per un posizionamento solido e duraturo nei risultati di ricerca.
Hai bisogno di un supporto per risolvere i contenuti duplicati SEO per il tuo sito? Contattami! Sarò felice di aiutarti.
CHI SONO
Mi chiamo Sara.
Sono Consulente SEO dal 2013.
Mi appassiona aiutare le aziende e le organizzazioni non-profit a far crescere la propria visibilità organica (ovvero non legata a dinamiche pubblicitarie a pagamento) attraverso i canali digitali, in particolare attraverso la ricerca su Google.
Quando non sono concentrata nell’aiutare i miei clienti, mi dedico a testare nuovi impasti per la pizza napoletana, leggere (soprattutto saggistica), sciare o fare escursioni sulle meravigliose Dolomiti.
Se vuoi conoscermi meglio e scoprire le aziende e realtà che ho potuto supportare nel corso della mia carriera, ti invito a visitare il mio sito web.
